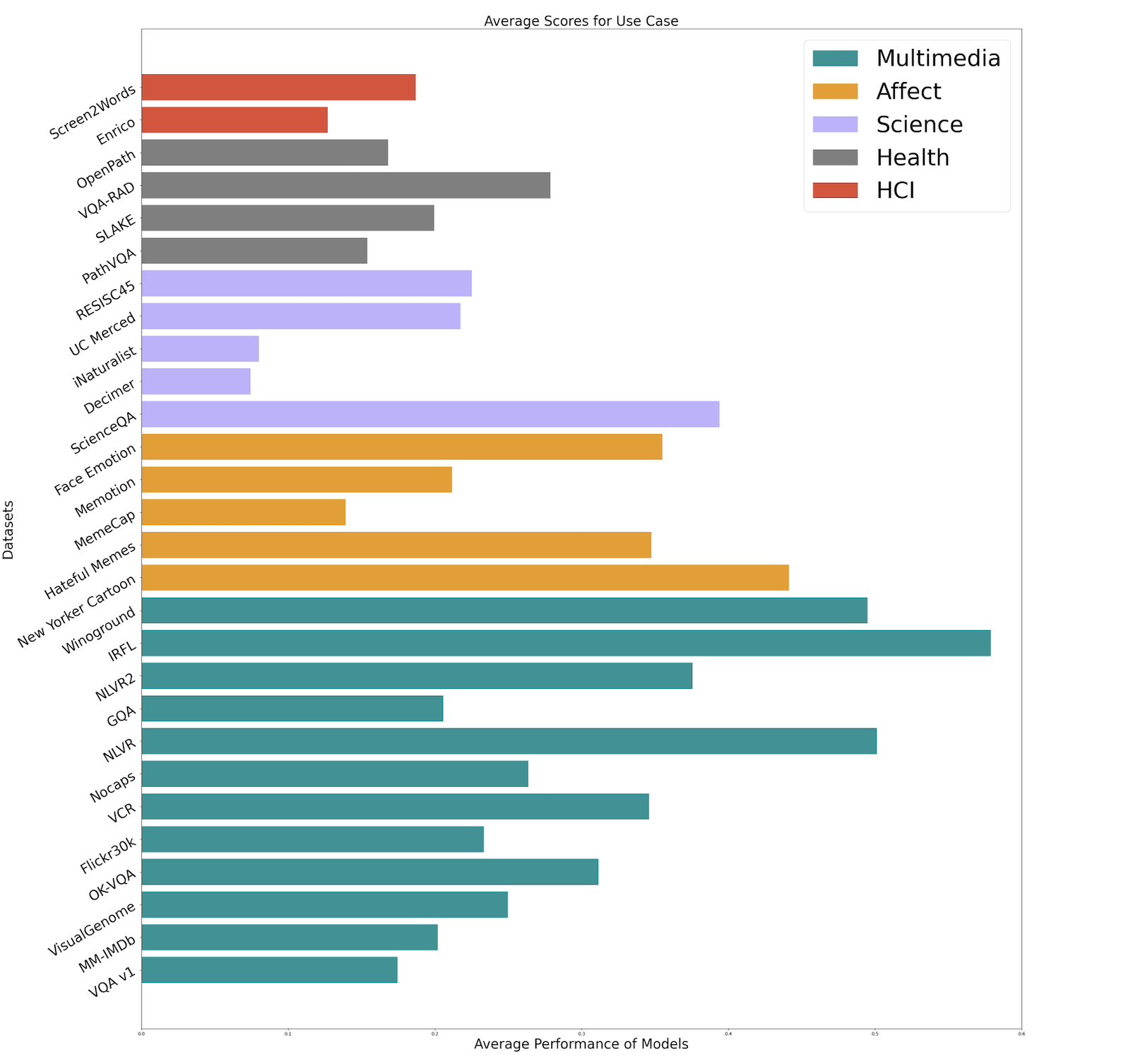
HEMM Overview
HEMM is an evaluation framework that characterizes multimodal models by several dimensions (size, architecture, pretraining objective, fine-tuning objective, training data) and emphasizes holistic benchmarking of these models at three disentangled levels:
-
Basic skills
Benchmarking models' abilities to address multimodal problems, such as multimodal interactions, multimodal alignment, reasoning across compositional features, and integration of external knowledge. -
Information flow
Benchmarking models' abilities to transform multimodal information during tasks such as querying, translation, editing, and fusion. -
Use cases
Benchmarking models' abilities to perform in real-world problems from multimedia, affective computing, natural sciences, healthcare, and human-computer interaction.
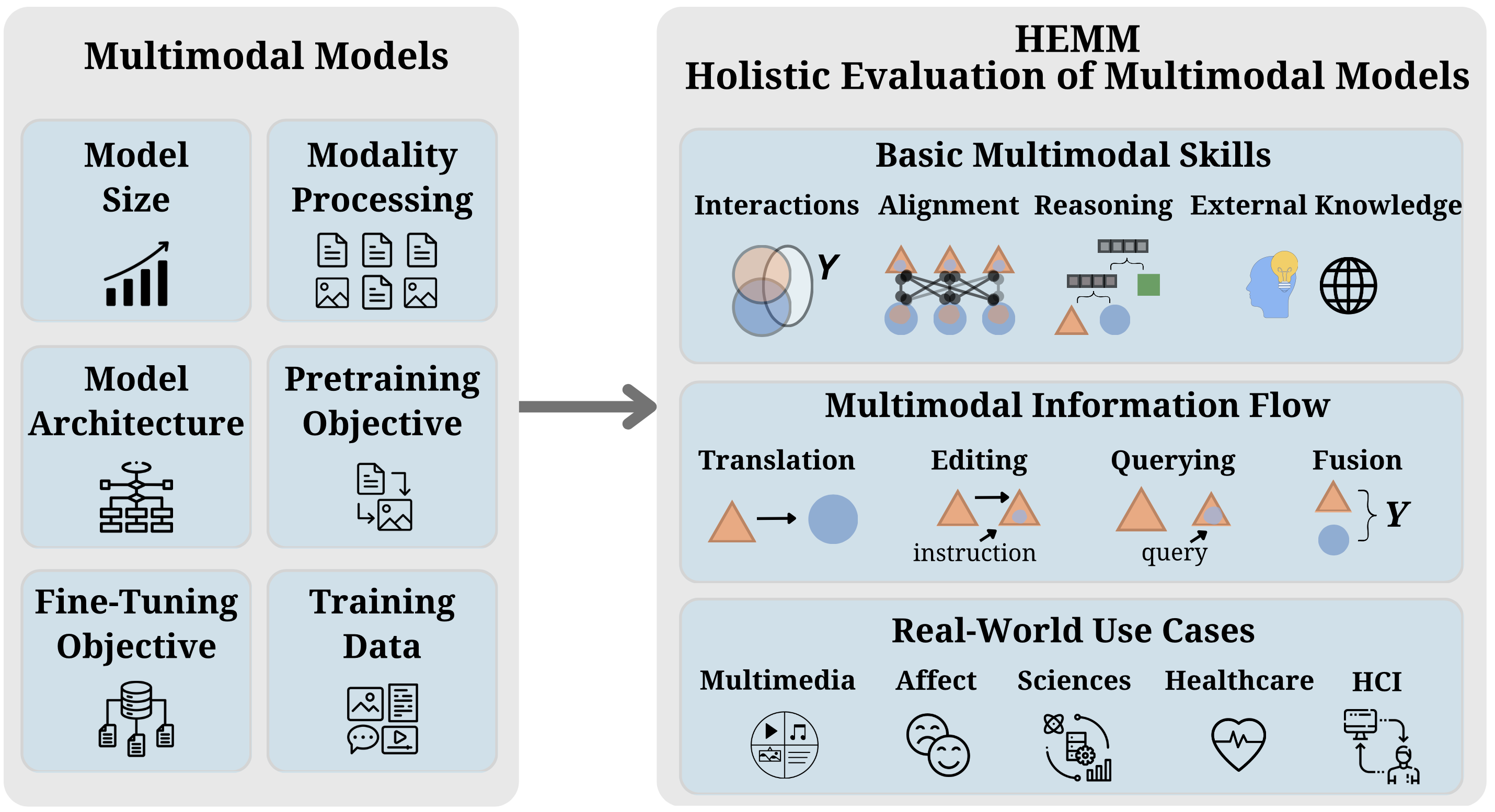
Figure1. HEMM benchmark overview
Key Challenges
Based on the holistic evaluation of multimodal models in HEMM, we identify several key challenges that multimodal models face in real-world applications. These challenges are as follows:
- Challenging Dataset
Health, HCI and Science datasets are relatiely difficult use cases for multimodal foundation models. - Multimodal Interactions
Models perform better on redundant interactions but struggle when visual information is not directly referenced by text. - Reasoning, fine-grained, and knowledge
We need better datasets that test for complex reasoning and fine-grained alignment - current ones do not pose enough challenges to today's models, with no significant performance differences with or without reasoning and fine-grained alignment. - Model and data size
Training on diverse data sources also improves over models that only pretrain on images and captions. The tasks that show the most improvement are iNaturalist and MemeCap which are knowledge intensive and require complex reasoning. - Model architecture and training
Aligning frozen pre-trained language and vision models outperforms end-to-end multimodal learning, and instruction-tuned models performed better than those with only supervised fine-tuning